
Stable diffusion models enable the generation of visuals and audio by using certain modern state-of-the-art methods. Stable Diffusion modifies input data under the guidance of text input and produces fresh, original output data.
But what exactly is stable diffusion? Basically, models of stable diffusion serve as latent diffusion models. It simulates, how the qualities of the input data diffuse over the latent space, it learns the latent structure of the input.
The deep generative neural network includes them. We employ original photographs, text, and other elements to steer the results, thus it is regarded as stable. An unstable diffusion, on the other hand, will be unpredictable.
On the other hand, let’s understand Img2img. Img2img often known as image-to-image, generates an image from a text prompt or an already-drawn image. The input uses the overall whole-look perspective of the existing image and uses the same color scheme.
In this manner, the input image serves as a roadmap. As a result, it wouldn’t matter if the image wasn’t well-designed or fully detailed.
Typical Uses For Stable Diffusion
Let’s quickly review three typical contexts for applying diffusion models:
Text-to-Image: This method creates related photos using a bit of text as a “prompt” rather than actual images.
Text-to-video: Diffusion models are used to create videos from text prompts in the text-to-video technique. Current research employs this in media to accomplish fascinating tasks like producing brief animated videos, song videos, and internet commercials while also illuminating ideas.
Text-to-3D: This method of stable diffusion creates 3D pictures from input text.
Applying diffusers can assist in producing free, original photographs. Your initiatives, resources, and even marketing brands will have content thanks to this. You can create your photos on your computer rather than paying a painter or photographer.
You can produce your own original audio instead of hiring a voice-over performer. Let’s examine Image-to-Image Generation next.
In this post, we will understand how the artists can use this to their advantage by first producing a "doodle" of the artwork they desire (i.e., a low-quality rendition of what will be the end result), and then inserting command through Stable Diffusion to create something of greater quality and with diverse styles.
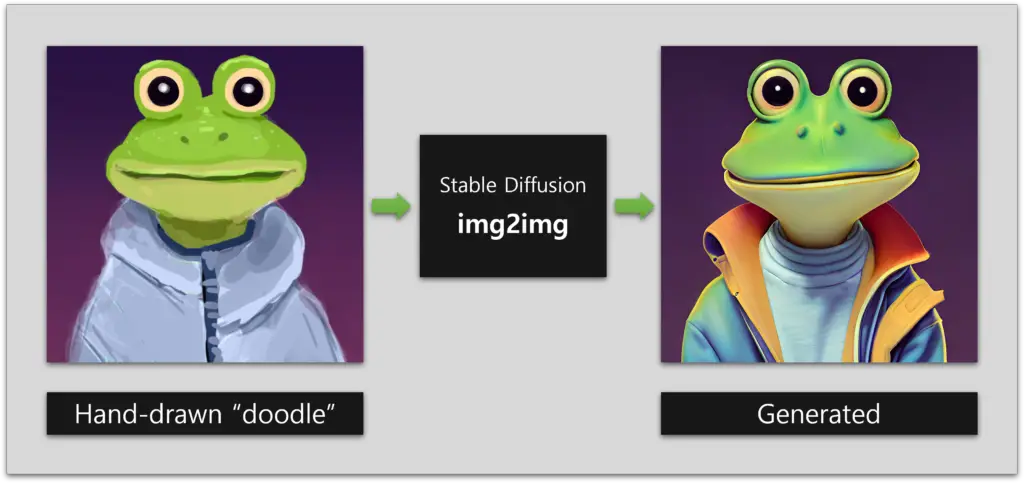
But How Does It Work?
For this article, we have explained the process by using AUTOMATIC1111 GUI, which offers an intuitive interface for the Img2Img process. The color sketch tool should now be activated so that we may either draw or add a picture for reference. The AUTOMATIC1111 GUI’s color sketch feature is by default disabled. But turns out to be the best for Img2Img procedure.
The Color Sketch Tool Can Be Activated As Shown Here:
When utilizing webui.py, include the following argument:
--gradio-img2img-tool color-sketch
Edit the webui-user.bat file located in the stable-diffusion-webui folder on Windows computers.
The line "set COMMANDLINE_ARGS=" should be changed to "set COMMANDLINE_ARGS=--gradio-img2img-tool color-sketch"
Before inserting the new text, ensure that there is a space. To open the GUI, double-click the file. This option is already turned on by default in the Colab Notebook Quick Start Guide. It’s time to learn how to use the color sketch tool after configuring it. The steps below explain how to utilize the color sketch tool.
Upload a file to the canvas using the AUTOMATIC1111 GUI’s Img2Img tab. The color sketch tool should now be accessible if you first click the color palette icon and then the solid color button. You can now add color to the sketches to give them more life and depth.
Stable diffusion is a generative model for image generation that uses a diffusion process to model data dispersion.
The “DDPM” (Diffusion Models with Discretely Composable Noise) presented by Ho et al. is one well-known example. Through the diffusion process, this approach assures stable image formation.
Suggested Read: – Best Stable Diffusion Pixel Art Prompts
The following is a high-level overview of the steps required in using stable diffusion for image generation:
1. PreprocessingTo begin, prepare the image dataset. This includes activities like normalizing pixel values to a range of [0, 1] and, if necessary, scaling or cropping the photos.
2. Diffusion Process The core of stable diffusion is an iterative method that adds noise to an image incrementally. During each cycle, the image is transformed in a multitude of ways. The goal is to train a model capable of reversing these modifications and recovering the original image. This method is done numerous times for each time step or diffusion step.
3. Noise Model Create a noise distribution (often a Gaussian distribution) to represent the noise that will be introduced to the image during each diffusion stage. The noise is introduced gradually, beginning with a slight variation and increasing it with each stage.
4. Model ArchitectureBuild a deep neural network architecture that can capture the reverse transition after each diffusion stage. This network takes a noisy image and predicts a clean image.
5. Training Utilize the image dataset to train the neural network. The goal is for the model to be able to learn the reverse transformation by decreasing the difference between anticipated and real clean images.
6. SamplingTo generate fresh images, begin with a random noise vector. Then, iteratively apply the learned reverse transformations for a predetermined number of diffusion steps. The end result will be a created image.
How To Use Stable Diffusion Img2img
Let’s walk through the process of creating a basic drawing into a polished piece of artwork now that the software has been configured and we are familiar with the color sketch tool.
Step 1: Set The Background
First, add a 512 by 512 pixel black or white background to the canvas. Your drawing will be built on top of this.
Step 2: Draw The Picture
Sketch the doodle using the color palette tool. Instead, then obsessing over every last detail, concentrate on capturing the color, form, and overall composition.
Step 3: Use Img2Img
It’s time to use the Img2Img approach now that you have your sketch in place. Take these actions:
- From the drop-down menu for the Stable Diffusion checkpoint, choose the v1-5-pruned-emaonly.ckpt.
- Make a prompt that describes your shot, such as “photo of a realistic banana with water droplets, and dramatic lighting.” Put this command into the text field.
- Set the sampling technique to DPM++ 2M Karras, the batch size to 4, the seed to -1 (random), the picture width and height to 512, and the sampling steps to 20.
- Set the sampling technique to DPM++ 2M Karras, the batch size to 4, the seed to -1 (random), the picture width and height to 512, and the sampling steps to 20.
- Try adjusting the denoising strength and CFG scale to get the right level of transformation.
- To create four new photos based on your input sketch and prompt, click Generate. Look over the created photographs, then save your favourite.
The Final Words !!
Users have access to Img2Img, which is driven by Stable Diffusion, for a flexible and efficient way to alter the structure and colors of an image. In comparison to the conventional text-to-image approach, this allows users greater control.
Even if you’ve never drawn before, you can quickly create works of art of professional quality by following this comprehensive guide.